Have you ever felt stuck when using Data Designer or the Rules Engine when you have data from two data sources that just don’t seem to have a common identifier? Or, more likely, you need to aggregate data at an account level for one dataset and then compare it to data aggregated at a higher level (either your entire customer base or perhaps a certain segment).
Either way, you need some kind of way to join that data...but how? That’s what this tutorial solves!
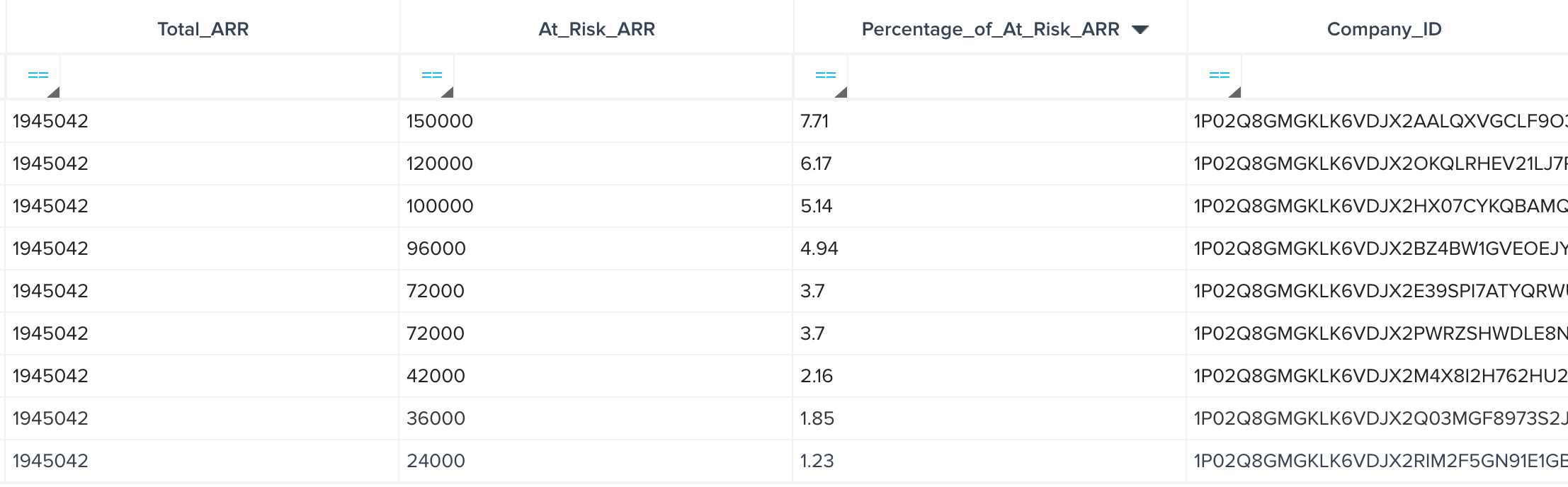
This tutorial stemmed from a real-world use case I put together for a customer who needed to compare ARR that was at risk per customer against the total ARR for the entire customer base. So if Customer ABC had an open risk CTA and had an ARR of $200,000, the customer needed to compare that against their total ARR (let’s say $2 million) and get a percentage of 10% for customer ABC.

In order to merge these two datasets that were aggregated at different levels, I created what I call an “artificial join” using a Case Expression in the Rules Engine for both datasets.
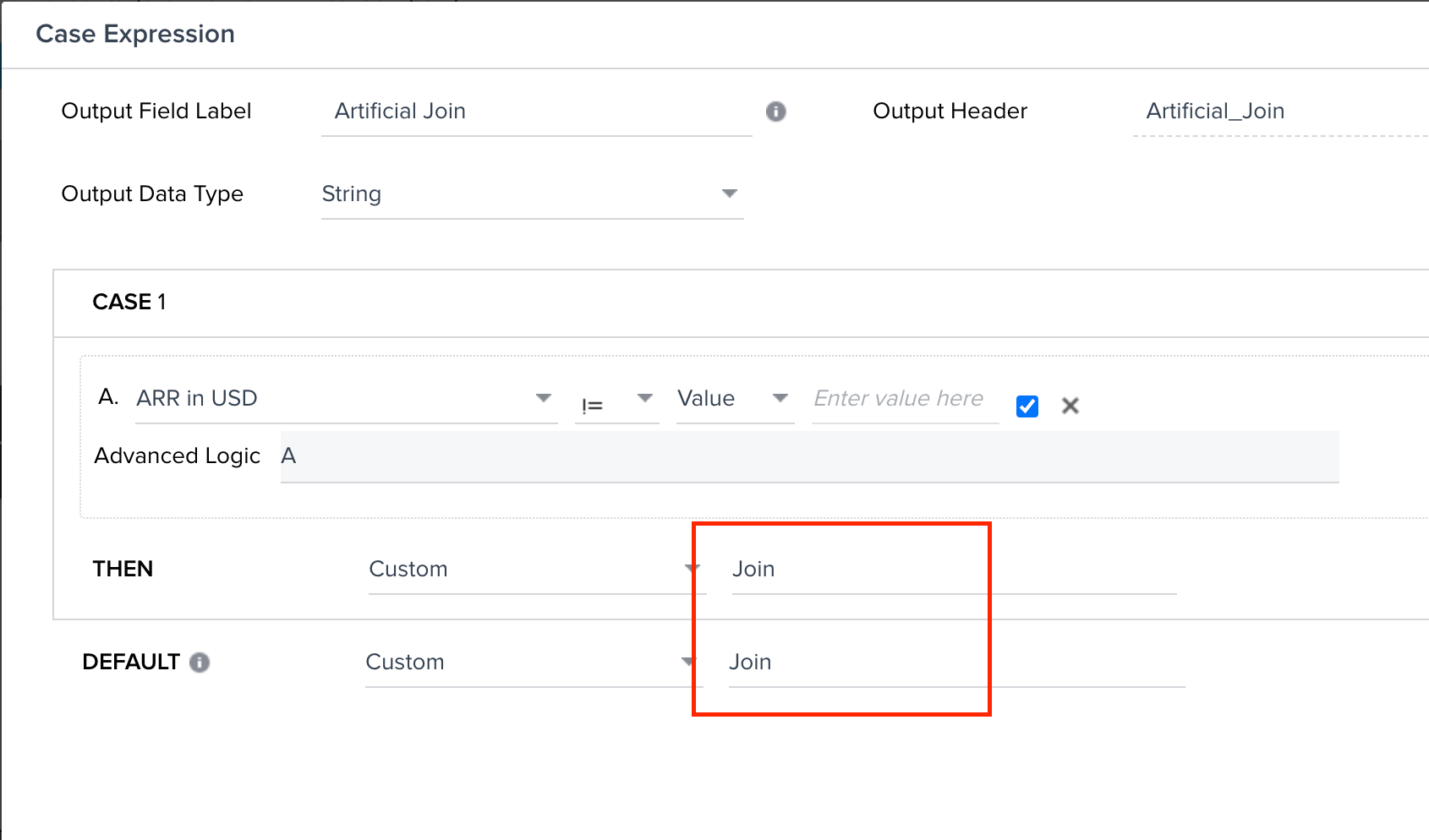
After manually creating that manual “Join” field, I was able to merge the two datasets together and then do one more transformation to calculate the percentage of at-risk ARR.
Voila, here’s our final dataset!