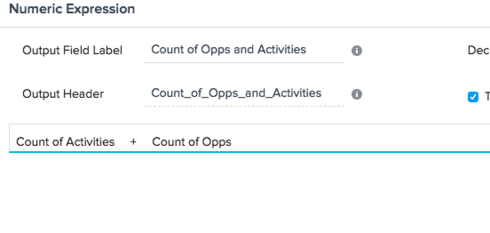
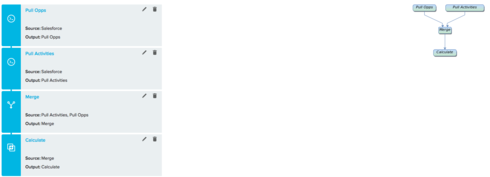However, because I can't include both "User Email" and "User Email" in the Show Fields,
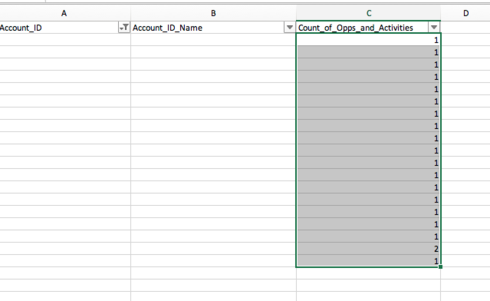
some of the email addresses are getting left off of the results and I'm left with data points (number of downloads, for example) that have no contact identification information.
I therefore can't load this data to the MDA table using this field as an identifier.
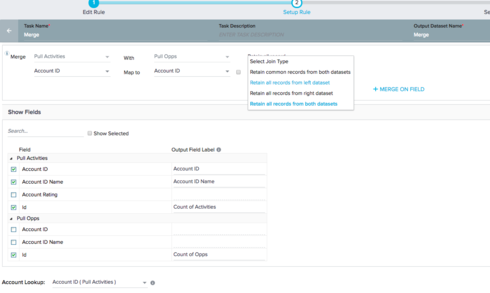
When I rename the fields to "User Email" "User Email 2" "User Email 3", etc, I am able to view the email for all results however I'm not sure of the best way to load this to the MDA table, as I now have multiple fields containing the email address.
Looking for some help or advice on how best to perform Outer Joins or to merge data when using the same field to merge on and identify data.
Best answer by dan_ahrens
View original