
It would be helpful if bionic rules allowed you to use GroupBy when adding a stat formula to the dataset.
Use case:
When calculating something like standard deviation and z-score for a customer's usage, I would like compare their most recent usage to their usage historically– for things like health score and CTAs.
If I can calculate a customer's average usage for the past X number of weeks and standard deviation for the distribution and weekly usage, I can compare the most recent week's usage to their historical average and know how significant the delta is for that customer.
The reason I would want to do this on a per-customer basis as opposed to calculating the stdev across all customers, is that we have (as I would imagine is the same as a lot of Gainsight customers) such a wide-range of usage patterns across customers. And I wouldn't necessarily want to compare, for instance, low-tier customer's usage against the aggregated average and stdev of all customers.
What's helpful to know, is "is a customer's most recent usage, in-line with what they usually do?" and if not, how significant is the change– positive or negative both good to know.
We do calculate stdev and z-score currently for some of our customers of product lines that we've had in Gainsight for a long time, but as we've added new product lines to our instance I thought I had a shorter route to getting this data with the new stat formulas available. Without being able to use GroupBy in conjunction with the stdev formula, there's just a bunch of additional steps needed to get to this.
Rules Engine: Allow stat functions to be grouped
None

Sign up
If you ever had a profile with us, there's no need to create another one.
Don't worry if your email address has since changed, or you can't remember your login, just let us know at community@gainsight.com and we'll help you get started from where you left.
Else, please continue with the registration below.
Welcome to the Gainsight Community
Enter your username or e-mail address. We'll send you an e-mail with instructions to reset your password.
Is it possible for you to share the screenshots of the rules that you are trying to configure and highlight the issues you are struggling with w.r.t the statistical functions ?
Regards,
Jitin
Here's the use case that we have where having stat functions be grouped would be helpful:
I have a dataset where I'm fetching weekly usage values for all accounts:
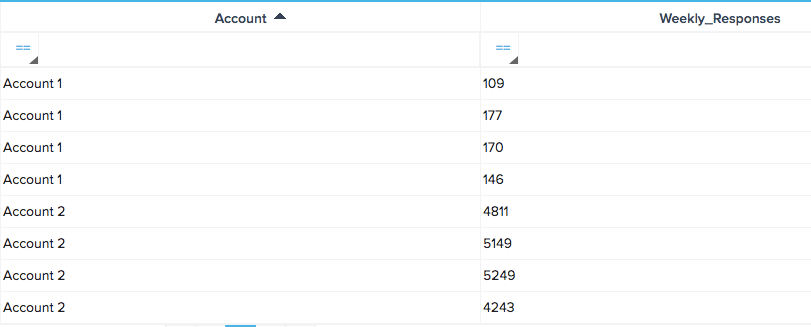
** the usage patterns here are pretty different from each other, but relatively consistent individually.Ideally, I'd be abe to transform the dataset from step one, add the standard deviation function, and group by Account ID (or Relationship ID where relavent). But currently, this isn't allowed in rules engine.
The only way the standard deviation function works today, is by removing the GroupBy field:
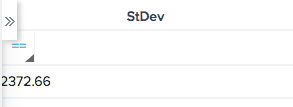
** StDev winds up being overstated (if thinking about accounts individually) because the variance is including both accounts with realy high usage and really low usage.The end result I really want is to know the standard deviation for each account individually, so that I can compare what customers did most recently to their individual usage patterns. e.g.:

** the two rows here are from the same accounts pictured in the screenshot above.Having this data allows us to set scorecard measures based on expected usage, and trigger CTAs when there is a statistically significant change in usage. e.g.:
Again, it's possible to do this with a combination of rules, MDA objects, and sfdc objects (b/c you eventually need a square root function not currently available in rules or MDA), but being able to do this in rules engine would save time, effort and storage.
Resurfacing an old post. We’re looking at a NXT migration and with Gainsight objects all moving to MDA, our team will need a new method for running stat functions by Customer/Relationship. MDA formulas are pretty limited (i.e. can’t do things like Sq. Root) and we’ve been using Customer Info and GS Relationship for stat calculations. Any consideration to this would be really appreciated.